Writing Better, Type-safe Code with Sorbet
Hey, I’m Jay and I recently finished my first internship at Shopify as a Backend Developer Intern on the App Store Ads team. Out of all my contributions to the ad platform, I wanted to talk about one that has takeaways for any Ruby developer. Here are four reasons for why we adopted Sorbet for static type checking in our repository.
1. Type-safe Method Calls
Let’s take a look at an example.
On the last line we call the method action and then call value.to_h on its return type. If action returns nil, calling value.to_h will cause an undefined method error.
Without a unit test covering the case when action returns nil, such code could go by undetected. To make matters worse, what if foo() is overridden by a child class to have a different return type? When types are inferred from the names of variables such as in the example, it is hard for any new developer to know that their code needs to handle different return types. There is no clue to suggest what result contains, so the developer would have to search the entire code base for what it could be.
Let’s see the same example with method signatures.
In the revised example, it’s clear from the signature that `action` returns a Result object or nil. Sorbet type checking will raise an error to say that calling action.value.to_h is invalid because action can potentially return nil. If Sorbet doesn’t raise any errors regarding our method, we deduce that foo() returns a Result object, as well as an object (most likely an array) that we can call empty? on. Overall, method annotations give us additional clarity and safety. Now, instead of writing trivial unit tests for each case, we let Sorbet check the output for us.
2. Type-safety for Complex Data Types
When passing complex data types around, it’s easy to use hashes such as the following:
This approach has a few concerns:
-
:idand:scoremay not be defined properties until the object is created in the database. If they’re not properties, callingad.idorad.scoreon the ad object will returnnil, which is unexpected behavior in certain contexts. -
:statemay be intended to be an enum. There are no runtime checks that ensure that a value such asrunningisn't accidentally put in the hash. -
:start_datehas a value, but:end_dateisnil. Can they both be nil? Will the:start_datealways have a value? We don’t know without looking at the code that generated the object.
Situations like this put a large onus on the developer to remember all the different variants of the hash and the contexts in which particular variants are used. It’s very easy for a developer to make a mistake by trying to access a key that doesn’t exist or assign the incorrect value to a key. Fortunately, Sorbet helps us solve these problems.
Consider the example of creating an ad:

Creating an ad
Input data flows from an API request to the database through some layers of code. Once stored, a database record is returned.
Here we define typed Sorbet structs for the input data and the output data. A Database::Ad extends an Input::Ad by additionally having an :id and :score.
Each of the previous concerns have been addressed:
-
:idand:scoreclearly do not exist on ads being sent to the database as inputs, but definitely exist on ads being returned. -
:statemust be aStateobject (as an aside, we implement these using Sorbet enums), so invalid strings cannot be assigned to:state. :end_datecan benil, but:start_datewill never benil.
Any failure to obey these rules will raise errors during static type checking by Sorbet, and it is clear to developers what fields exist on our object when it’s being passed through our code.
To extend beyond the scope of this article, we use GraphQL to specify type contracts between services. This lets us guarantee that ad data sent to our API will parse correctly into Input::Ad objects.
3. Type-safe Polymorphism and Duck Typing
Sorbet interfaces are integral to implementing the design patterns used in the Ad Platform repository. We’re committed to following a Hexagonal Structure with dependency injection:
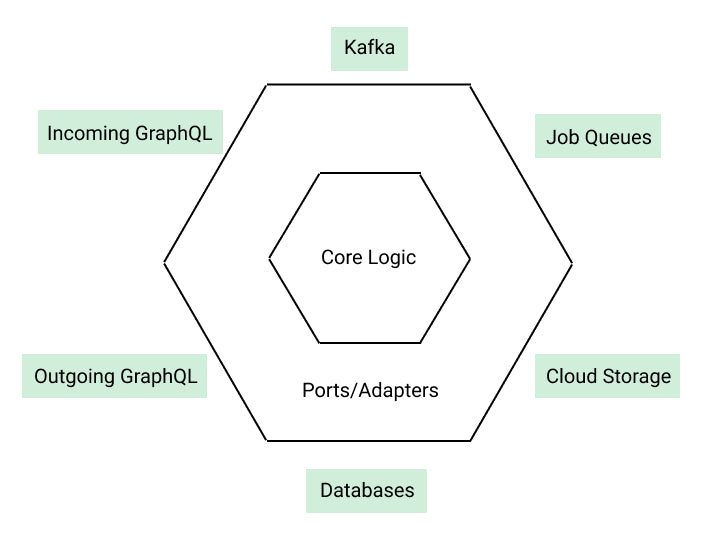
Hexagonal Structure with dependency injection
When we get an incoming request, we first compose a task to execute some logic by injecting the necessary ports/adapters. Then we execute the task and return its result. This architecture makes it easy to work on components individually and isolate logic for testing. This leads to very organized code, fast unit tests, and high maintainability—however, this strategy relies on explicit interfaces to keep contracts between components.
Let’s see an example where errors can easily occur:
In the example method, we call Action.perform with either a SynchronousIndexer or an AsynchronousIndexer. Both implement the index method in a different manner. For example, the AsynchronousIndexer may enqueue a job via a job queue, whereas the SynchronousIndexer may store values in a database immediately. The problem is that there’s no way to know if both indexers have the index method or if they return the correct result type expected by Action.perform.
In this situation, Sorbet interfaces are handy:
We define a module called Indexer that serves as our interface. AsynchronousIndexer and SynchronousIndexer as classes which implement this interface, which means that they both implement the index method. The index method must take in an array of keyword strings, and return a Result object as well as a list of errors.
Now we can modify action to take an Indexer as a parameter so that it’s guaranteed that the indexer provided will implement the index method as expected. Now it’s clear to a developer what types are being used and it also ensures that the code behaves as expected.
4. Support for Gradual Refactoring
One roadblock to adding Sorbet to an entire codebase is that it’s a lot of work to refactor every file to be typed. Fortunately, Sorbet supports gradual typing. It statically types your codebase on a file-by-file level, so one can refactor at their own pace. A nice feature is that it comes with 5 different typing strictness levels, so one can choose the level of granularity. These levels also allow for gradual adoption across files in a codebase.
On the ads team, we decided to refactor using a namespace-by-namespace scheme. When a particular Github issue requires committing to a set of files in the same namespace, we upgrade those to the minimum typed level of true, adding method signatures, interfaces, enums, and structs as needed.
Enforcing Type Safety Catches Errors
Typing our methods and data types with Sorbet encourages us to adhere to our design patterns more strictly. Sticking to our patterns keeps our code organized and friendly to developers while also discouraging duplication and bad practices. Enforcing type safety in our code saves us from shipping unsafe code to production and catches errors that our unit tests may not catch.
We encourage everyone to try it in their projects!
We're always on the lookout for talent and we’d love to hear from you. Visit our Engineering career page to find out about our open positions.