
By Jay Lim and Gannon McGibbon
At Shopify, we believe in highly aligned, loosely coupled teams to help us move fast. Since we have many teams working independently on a large monolithic Rails application, inefficiencies in code are sometimes inadvertently added to our codebase. Over time, these problems can add up to serious performance regressions.
By the time such performance regressions are noticeable, it might already be too late to track offending commits down. This can be exceedingly challenging on codebases with thousands of changes being committed each day. How do we effectively find out why our application is slow? Even if we have a fix for the slow code, how can we prove that our new code is faster?
It all starts with profiling and benchmarking. Last year, we wrote about writing fast code in Ruby on Rails. Knowing how to write fast code is useful, but insufficient without knowing how to fix slow code. Let’s talk about the approaches that we can use to find slow code, fix it, and prove that our new solution is faster. We’ll also explore some case studies that feature real world examples on using profiling and benchmarking.
Profiling
Before we dive into fixing unperformant code, we need to find it first. Identifying code that causes performance bottlenecks can be challenging in a large codebase. Profiling helps us to do so easily.
What is Profiling?
Profiling is a type of program analysis that collects metrics about the program at runtime, such as the frequency and duration of method calls. It’s carried out using a tool known as a profiler, and a profiler’s output can be visualized in various ways. For example, flat profiles, call graphs, and flamegraphs.
Why Should I Profile My Code?
Some issues are challenging to detect by just looking at the code (static analysis, code reviews, etc.). One of the main goals of profiling is observability. By knowing what is going on under the hood during runtime, we gain a better understanding of what the program is doing and reason about why an application is slow. Profiling helps us to narrow down the scope of a performance bottleneck to a particular area.
How Do I Profile?
Before we figure out what to profile, we need to first figure out what we want to know: do we want to measure elapsed time for a specific code block, or do we want to measure object allocations in that code block? In terms of granularity, do we need elapsed time for every single method call in that code block, or do we just need the aggregated value? Elapsed time here can be further broken down into CPU time or wall time.
For measuring elapsed time, a simple solution is to measure the start time and the end time of a particular code block, and report the difference. If we need a higher granularity, we do this for every single method. To do this, we use the TracePoint API in Ruby to hook into every single method call made by Ruby. Similarly, for object allocations, we use the ObjectSpace module to trace object allocations, or even dump the Ruby heap to observe its contents.
However, instead of building custom profiling solutions, we can use one of the available profilers out there, and each has its own advantages and disadvantages. Here are a few options:
1. rbspy
rbspy samples stack frames from a Ruby process over time. The main advantage is that it can be used as a standalone program without needing any instrumentation code.
Once we know the Ruby Process Identifier (PID) that we want to profile, we start the profiling session like this:
rbspy record —pid $PID
2. stackprof
Like rbspy, stackprof samples stack frames over time, but from a block of instrumented Ruby code. Stackprof is used as a profiling solution for custom code blocks:
profile = StackProf.run(mode: :cpu) do
# Code to profile
end
The rack-mini-profiler gem is a fully-featured profiling solution for Rack-based applications. Unlike the other profilers described in this section, it includes a memory profiler in addition to call-stack sampling. The memory profiler collects data such as Garbage Collection (GC) statistics, number of allocations, etc. Under the hood, it uses the stackprof and memory_profiler gems.
4. app_profiler
app_profiler is a lightweight alternative to rack-mini-profiler. It contains a Rack-only middleware that supports call-stack profiling for web requests. In addition to that, block level profiling is also available to any Ruby application. These profiles can be stored in a configurable storage backend such as Google Cloud Storage, and can be visualized through a configurable viewer such as Speedscope, a browser-based flamegraph viewer.
At Shopify, we collect performance profiles in our production environments. Rack Mini Profiler is a great gem, but it comes with a lot of extra features such as database and memory profiling, and it seemed too heavy for our use case. As a result, we built App Profiler that similarly uses Stackprof under the hood. Currently, this gem is used to support our on-demand remote profiling infrastructure for production requests.
Case Study: Using App Profiler on Shopify
An example of a performance problem that was identified in production was related to unnecessary GC cycles. Last year, we noticed that a cart item with a very large quantity used a ridiculous amount of CPU time and resulted in slow requests. It turns out, the issue was related to Ruby allocating too many objects, triggering the GC multiple times.
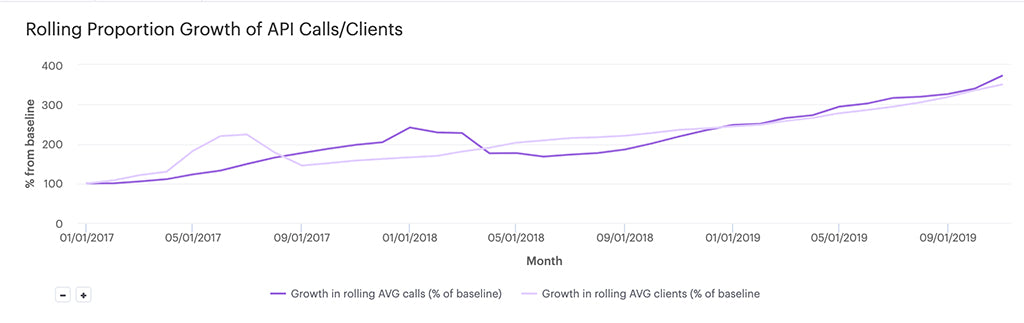
The figure below illustrates a section of the flamegraph for a similar slow request, and the section corresponds to approximately 500ms of CPU time.

A section of the flamegraph for a similar slow request
The highlighted chunks correspond to the GC operations, and they interleave with the regular operations. From this section, we see that GC itself consumed about 35% of CPU time, which is a lot! We inferred that we were allocating too many Ruby objects. Without profiling, it’s difficult to identify these kinds of issues quickly.
Benchmarking
Now that we know how to identify performance problems, how do we fix them? While the right solution is largely context sensitive, validating the fix isn’t. Benchmarking helps us prove performance differences in two or more different code paths.
What is Benchmarking?
Benchmarking is a way of measuring the performance of code. Often, it’s used to compare two or more similar code paths to see which code path is the fastest. Here’s what a simple ruby benchmark looks like:
This code snippet is benchmarking at its simplest. We’re measuring how long a method takes to run in seconds. We could extend the example to measure a series of methods, a complex math equation, or anything else that fits into a block. This kind of instrumentation is useful because it can unveil regression or improvement in speed over time.
While wall time is a pretty reliable measurement of “performance”, there’s other methods one can measure code by besides realtime, the Ruby standard library’s Benchmark module includes bm and bmbm.
The bm method shows a more detailed breakdown of timing measurements. Let’s take a look at a script with some output:
User, system, and total are all different measurements of CPU time. User refers to time spent working in user space. Similarly, system denotes time spent working in kernel space. Total is the sum of CPU timings, and real is the same wall time measurement we saw from Benchmark.realtime.
What about bmbm? Well, it is exactly the same as bm with one unique difference. Here’s what the output looks like:
The rehearsal, or warmup step is what makes bmbm useful. It runs benchmark code blocks once before measuring to prime any caching or similar mechanism to produce more stable, reproducible results.
Lastly, let’s talk about the benchmark-ips gem. This is the most common method of benchmarking Ruby code. You’ll see it a lot in the wild, this is what a simple script looks like:
Here, we’re benchmarking the same method using familiar syntax with ips method. Notice the inline bundler and gemfile code. We need this in a scripting context because benchmark-ips isn’t part of the standard library. In a normal project setup, we add gem entries to the Gemfile as usual.
The output of this script is as follows:
Ignoring the bundler output, we see the warmup iteration score per 100 milliseconds ran for the default of 2 seconds, and how many times the code block was able to run in 5 seconds. It’ll become more apparent why benchmark-ips is so popular later.
Why Should I Benchmark My Code?
So, now we know what benchmarking is and some tools available to us. But why even bother benchmarking at all? It may not be immediately obvious why benchmarking is so valuable.
Benchmarks are used to quantify the performance of one or more blocks of code. This becomes very useful when there are performance questions that need answers. Often, these questions boil down to “which is faster, A or B?”. Let’s look at an example:
In this script, we’re doing most of what we did in the first benchmark-ips example. Pay attention to the addition of another method, and how it changes the benchmark block. When benchmarking more than one thing at once, simply add another report block. Additionally, the compare! method prints a comparison of all reports:
Wow, that’s pretty snazzy! compare! is able to tell us which benchmark is slower and by how much. Given the amount of thread sleeping we’re doing in our benchmark subject methods, this aligns with our expectations.
Benchmarking can be a means of proving how fast a given code path is. It’s not uncommon for developers to propose a code change that makes a code path faster without any evidence.
Depending on the change, comparison can be challenging. As in the previous example, benchmark-ips may be used to benchmark individual code paths. Running the same single report benchmark on versions of code easily tests pre and post patch performance.
How Do I Benchmark My Code?
Now we know what benchmarking is and why it is important. Great! But how do you get started benchmarking in an application? Trivial examples are easy to learn from but aren’t very relatable.
When developing in a framework like Ruby on Rails, it can be difficult to understand how to set up and load framework code for benchmark scripts. Thankfully, one of the latest features of Ruby on Rails can generate benchmarks automatically. Let’s take a look:
This benchmark can be generated by running bin/rails generate benchmark my_benchmark, placing a file in script/benchmarks/my_benchmark.rb. Note the inline gemfile isn’t required because we piggyback off of the Rails app’s Gemfile. The benchmark generator is slated for release in Rails 6.1.
Now, let’s look at a real world example of a Rails benchmark:
In this example, we’re subclassing Order and caching the calculation it does to find the total price of all line items. While it may seem obvious that this would be a beneficial code change, it isn’t obvious how much faster it is compared to the base implementation. Here’s a more unabridged version of the script for full context.
Running the script reveals a ~50x improvement to a simple order of 4 line items. With orders with more line items, the payoff only gets better.
One last thing to know about benchmarking effectively is being aware of micro-optimization. These are optimizations that are so small, the performance improvement isn’t worth the code change. While these are sometimes acceptable for hot code paths, it’s best to tackle larger scale performance issues first.
Case Study: Rails Contributions
As with many open source projects, Ruby on Rails usually requires performance optimization pull requests to include benchmarks. The same is common for new features to performance sensitive areas like Active Record query building or Active Support’s cache stores. In the case of Rails, most benchmarks are made with benchmark-ips to simplify comparison.
For example, https://github.com/rails/rails/pull/36052 changes how primary keys are accessed in Active Record instances. Specifically, refactoring class method calls to instance variable references. It includes before and after benchmark results with a clear explanation of why the change is necessary.
https://github.com/rails/rails/pull/38401 changes model attribute assignment in Active Record so that key stringification of attribute hashes is no longer needed. A benchmark script with multiple scenarios is provided with results. This is a particularly hot codepath because creating and updating records is at the heart of most Rails apps.
Another example, https://github.com/rails/rails/pull/34197 reduces object allocations in ActiveRecord#respond_to?. It provides a memory benchmark that compares total allocations before and after the patch, with a calculated diff. Reducing allocations delivers better performance because the less Ruby allocates, the less time Ruby spends assigning objects to blocks of memory.
Final Thoughts
Slow code is an inevitable facet of any codebase. It isn’t important who introduces performance regressions, but how they are fixed. As developers, it’s our job to leverage profiling and benchmarking to find and fix performance problems.
At Shopify, we’ve written a lot of slow code, often for good reasons. Ruby itself is optimized for the developer, not the servers we run it on. As Rubyists, we write idiomatic, maintainable code that isn’t always performant, so profile and benchmark responsibly, and be wary of micro-optimizations!
Additional Information
If this sounds like the kind of problems you want to solve, we're always on the lookout for talent and we’d love to hear from you. Visit our Engineering career page to find out about our open positions. Learn about the actions we’re taking as we continue to hire during COVID‑19


 Function foo with optimization
Function foo with optimization

















 Sam Saffron presenting at Shopify in Ottawa
Sam Saffron presenting at Shopify in Ottawa


















































 Binding the experiment logic
Binding the experiment logic Surfacing the purchase experience
Surfacing the purchase experience














































 Welcome back to another installment of Developing Shopify Apps!
Welcome back to another installment of Developing Shopify Apps!



















 Let's get the same information that we got from the admin panel's General Settings page, but using the API this time. In order to do this, we need to know two things:
Let's get the same information that we got from the admin panel's General Settings page, but using the API this time. In order to do this, we need to know two things:







































