
Under Deconstruction: The State of Shopify’s Monolith
Ruby on Rails is a great framework for rapidly building beautiful web applications that users and developers love. But if an application is successful, there’s usually continued investment, resulting in additional features and increased overall system complexity.
Shopify’s core monolith has over 2.8 million lines of Ruby code and 500,000 commits. Rails doesn’t provide patterns or tooling for managing the inherent complexity and adding features in a structured, well-bounded way.
That’s why, over three years ago, Shopify founded a team to investigate how to make our Rails monoliths more modular. The goal was to help us scale towards ever increasing system capabilities and complexity by creating smaller, independent units of code we called components. The vision went like this:
- We can more easily onboard new developers to just the parts immediately relevant to them, instead of the whole monolith.
- Instead of running the test suite on the whole application, we can run it on the smaller subset of components affected by a change, making the test suite faster and more stable.
- Instead of worrying about the impact on parts of the system we know less well, we can change a component freely as long as we’re keeping its existing contracts intact, cutting down on feature implementation time.
In summary, developers should feel like they are working on a much smaller app than they actually are.
It’s been 18 months since we last shared our efforts to make our Rails monoliths more modular. I’ve been working on this modularity effort for the last two and a half years, currently on a team called Architecture Patterns. I’ll lay out the current state of my team’s work, and some things we’d do differently if we started fresh right now.
The Status Quo
We generally stand by the original ideas as described in Deconstructing the Monolith, but almost all of the details have changed. We make consistent progress, but it's important to note that making changes at this scale requires a significant shift in thinking for a critical mass of contributors, and that takes time.
While we’re far from finished, we already reap the benefits of our work. The added constraints on how we write our code trigger deep software design discussions throughout the organization. We see a mindset shift across our developers with a stronger focus on modular design. When making a change, developers are now more aware of the consequences on the design and quality of the monolith as a whole. That means instead of degrading the design of existing code, new feature implementations now more often improve it. Parts of the codebase that received heavy refactoring in recent years are now easier to understand because their relationship with the rest of the system is clearer.
We automatically triage exceptions to components, enabling teams to act on them without having to dig through the sometimes noisy exception stream for the whole monolith. And with each component explicitly owned by a team, whole-codebase chores like Rails upgrades are easily distributed and collaboratively solved. Shopify is running its main monolith on the newest, unreleased revisions of Rails. The clearly defined ownership for areas of the codebase is one of the factors enabling us to do that.
What We Learned so Far
Our main monolith is one of the oldest, largest Rails codebases on the planet, under continuous development since at least 2006, with hundreds of developers currently adding features.
A refactor on this scale needs to be approached completely differently from smaller efforts. We learned that all large scale changes start
- with understanding and influencing developer behavior
- at the grassroots
- with a holistic perspective on architecture
- with careful application of tooling
- with being aware of the tradeoffs involved
Understand Developer Behaviour
A single centralized team can’t make change happen by working against the momentum of hundreds of developers adding features.
Also, it can’t anticipate all the edge cases and have context on all domains of the application. A single team can make simple change happen on a large scale, or complex change on a small scale. To modularize a large monolith though, we need to make complex change happen on a large scale. Even if a centralized team could make it happen, the design would degrade once the team switches its focus to something else.
That’s why making a fundamental architecture change to a system that’s being actively worked on is in large part a people problem. We need to change the behavior of the average developer on the codebase. We need to all iteratively evolve the system towards the envisioned future together. The developers are an integral part of the system.
Dr. B.J. Fogg, founder of the Behavior Design Lab at Stanford University, developed a model for thinking about behaviors that matches our experiences. The model suggests that for a behavior to occur, three things need to be in place: Ability, Motivation, and Prompt.

Fogg Behaviour Model by BJ Fogg, PHD
In a nutshell, prompts are necessary for a desired behavior to happen, but they're ineffective unless there's enough motivation and ability. Exceptionally high motivation can, within reason, compensate for low ability and vice versa.
Automated tooling and targeted manual code reviews provide prompts. That’s the easy part. Creating ability and motivation to make positive change is harder. Especially when that goes against common Ruby on Rails community practices and requires a view of the system that’s much larger than the area that most individual developers are working on. Spreading an understanding of what we’re aiming for, and why, is critical.
For example, we invested quite a bit of time and energy into developing patterns to ensure some consistency in how component boundary interfaces are designed. Again and again we pondered: How should components call each other? We then pushed developers to use these patterns everywhere. In hindsight, this strategy didn’t increase developer ability or motivation. It didn’t solve the problems actually holding them back, and it didn’t explain the reasons or long term goals well enough. Pushing for consistency added rules, which always add some friction, because they have to be learned, remembered, and followed. It didn’t make any hard problem significantly easier to solve. In some cases, the patterns were helpful. In other cases, they lead developers to redefine their problem to fit the solution we provided, which degraded the overall state of the monolith.
Today, we’re still providing some general suggestions on interface consistency, but we have a lot less hard rules. We’re focusing on finding the areas where developers are hungry to make positive change, but don’t end up doing it because it’s too hard. Often, making our code more modular is hard because legacy code and tooling are based on assumptions that no longer hold true. One of the most problematic outdated assumptions is that all Active Record models are OK to access everywhere, when in this new componentized world we want to restrict their usage to the component that owns them. We can help developers overcome this problem.
So in the words of Dr. Fogg, these days we’re looking for areas where the prompt is easy, the motivation is present, and we just have to amp up the ability to make things happen.
Foster the Grassroots
As I mentioned, we, as a centralized team, can’t make this change happen by ourselves. So, we work to create a grassroots movement among the developers at Shopify. We aim to increase the number of people that have ability, motivation and prompt to move the system a tiny step further in the right direction.
We give internal talks, write documentation, share wins, embed in other teams, and pair with people all over the company. Embedding and pairing make sure we’re solving the problems that product developers are most struggling with in practice, avoiding what’s often called Ivory Tower Syndrome where the solutions don’t match the problems. It also lets us gain context on different areas of the codebase and the business while helping motivated people achieve goals that align with ours.
As an example, we have a group called the Architecture Guild. The guild has a slack channel for software architecture discussions and bi-weekly meetups. It’s an open forum, and a way to grow more architecture conscious mindsets while encouraging architectural thinking. The Architecture Patterns team provides some content that we think is useful, but we encourage other people to share their thoughts, and most of the contributions come from other teams. Currently, the Architecture Guild has ~400 members and 54 documented meetups with meeting notes and recordings that are shared with all developers at Shopify.
The Architecture Guild grew organically out of the first Componentization team at Shopify after the first year of Componentization. If I were to start a similar effort again today, I’d establish a forum like this from the beginning to get as many people on board with the change as early as possible. It’s also generally a great vehicle to spread software design knowledge that’s siloed in specific teams to other parts of the company.
Other methods we use to create fertile ground for ambitious architecture projects are
- the Developer Handbook, an internal online resource documenting how we develop software at Shopify.
- Developer Talks, our internal weekly livestreamed and recorded talks about software development at Shopify.
Build Holistic Architecture
Some properties of software are so closely related that they need to be approached in pairs. By working on one property and ignoring its “partner property,” you could end up degrading the system.
Balance Encapsulation With A Simple Dependency Graph
We started out by focusing our work on building a clean public interface around each component to hide the internals. The expectation was that this would allow reasoning about and understanding the behavior of a component in isolation. Changing internals of a component wouldn’t break other components—as long as the interface stays stable.
It’s not that straightforward though. The public interface is what other components depend on; if a lot of components depend on it, it’s hard to change. The interface needs to be designed with those dependencies in mind, and the more components depend on it, the more abstract it needs to be. It’s hard to change because it’s used everywhere, and it will have to change often if it contains knowledge about concrete parts of the business logic.
When we started analyzing the graph of dependencies between components, it was very dense, to the point that every component depended on over half of all the other components. We also had lots of circular dependencies.

Circular Dependancies
Circular dependencies are situations where for example component A depends on component B but component B also depends on component A. But circular dependencies don’t have to be direct, the cycles can be longer than two. For example, A depends on B depends on C depends on A.
These properties of the dependency graph mean that the components can’t be reasoned about, or evolved, separately. Changes to any component in a cycle can break all other components in the cycle. Changes to a component that has almost all other components depend on can break almost all other components. So these changes require a lot of context. A dense, cyclical dependency graph undermines the whole idea of Componentization—it blocks us from making the system feel smaller.
When we ignored the dependency graph, in large parts of the codebase the public interface turned out to just be an added layer of indirection in the existing control flows. This made it harder to refactor these control flows because it added additional pieces that needed to be changed. It also didn’t make it a lot easier to reason about parts of the system in isolation.

The simplest possible way to introduce a public interface to a private implementation
The diagram shows that the simplest possible way to introduce a public interface could just mean that a previously problematic design is leaked into a separate interface class, making the underlying design problem harder to fix by spreading it into more files.
Discussions about the desirable direction of a dependency often surface these underlying design problems. We routinely discover objects with too many responsibilities and missing abstractions this way.
Perhaps not surprisingly, one of the central entities of the Shopify system is the Shop and so almost everything depends on the Shop class. That means that if we want to avoid circular dependencies, the Shop class can depend on almost nothing.
Luckily, there are proven tools we can use to straighten out the dependency graph. We can make arrows point in different directions, by either moving responsibilities into the component that depends on them or applying inversion of control. Inversion of control means to invert a dependency in such a way that control flow and source code dependency are opposed. This can be done for example through a publish/subscribe mechanism like ActiveSupport::Notifications.
This strategy of eliminating circular dependencies naturally guides us towards removing concrete implementation from classes like Shop, moving it towards a mostly empty container holding only the identity of a shop and some abstract concepts.
If we apply the aforementioned techniques while building out the public interfaces, the result is therefore much more useful. The simplified graph allows us to reason about parts of the system in isolation, and it even lays out a path towards testing parts of the system in isolation.
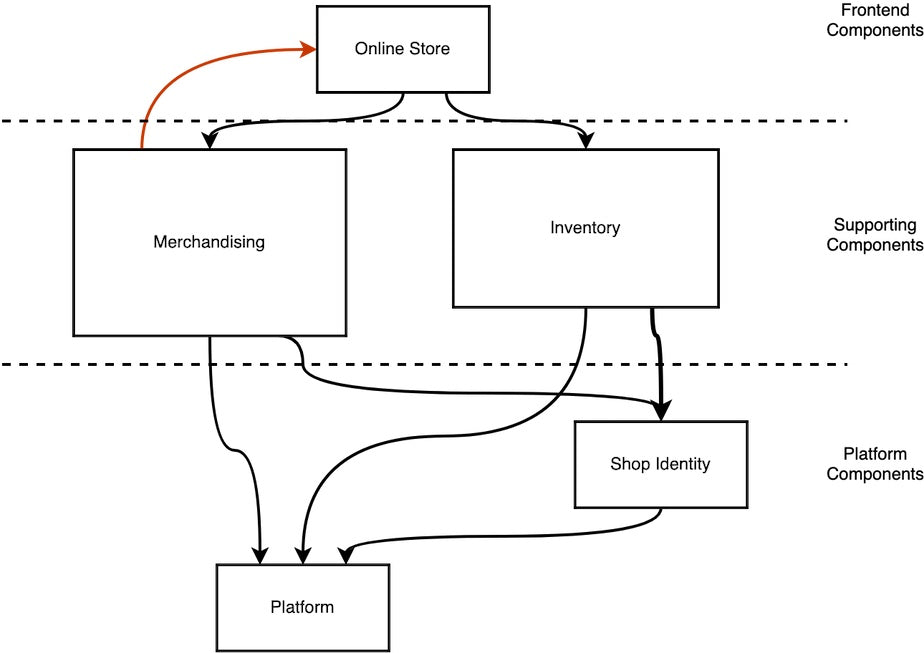
Dependencies diagram between Platform, Supporting, and Frontend components
If determining the desired direction of all the dependencies on a component ever feels overwhelming, we think about the components grouped into layers. This allows us to prioritize and focus on cleaning up dependencies across layers first. The diagram above sketches out an example. Here, we have platform components, Platform and Shop Identity, that purely provide functionality to other components. Supporting components, like Merchandising and Inventory, depend on the platform components but also provide functionality to others and often serve their own external APIs. Frontend components, like Online Store, are primarily externally facing. The dependencies crossing the dotted lines can be prioritized and cleaned up first, before we look at dependencies within a layer, for example between Merchandising and Inventory.
Balance Loose Coupling With High Cohesion

Tight coupling with low cohesion and loose coupling with high cohesion
Meaningful boundaries like those we want around components require loose coupling and high cohesion. A good approximation for this is Change Locality: The degree to which code that changes together lives together.
At first, we solely focused on decoupling components from each other. This felt good because it was an easy, visible change, but it still left us with cohesive parts of the codebase that spanned across component boundaries. In some cases, we reinforced a broken state. The consequence is that often small changes to the functionality of the system still meant changes in code across multiple components, for which the developers involved needed to know and understand all of those components.
Change Locality is a sign of both low coupling and high cohesion and makes evolving the code easier. The codebase feels smaller, which is one of our stated goals. And Change Locality can also be made visible. For example, we are working on automation analyzing all pull requests on our codebase for which components they touch. The number of components touched should go down over time.
An interesting side note here is that different kinds of cohesion exist. We found that where our legacy code respects cohesion, it’s mostly informational cohesion—grouping code that operates on the same data. This arises from a design process that starts with database tables (very common in the Rails community). Change Locality can be hindered by that. To produce software that is easy to maintain, it makes more sense to focus on functional cohesion—grouping code that performs a task together. That’s also much closer to how we usually think about our system.
Our focus on functional cohesion is already showing benefits by making our business logic, the heart of our software, easier to understand.
Create a SOLID foundation
There are ideas in software design that apply in a very similar way on different levels of abstraction—coupling and cohesion, for example. We started out applying these ideas on the level of components. But most of what applies to components, which are really large groups of classes, also applies on the level of individual classes and even methods.
On a class level, the most relevant software design ideas are commonly summarized as the SOLID principles. On a component level, the same ideas are called “package principles.” Here’s a SOLID refresher from Wikipedia:
Single-responsibility principle
A class should only have a single responsibility, that is, only changes to one part of the software's specification should be able to affect the specification of the class.
Open–closed principle
Software entities should be open for extension, but closed for modification.
Liskov substitution principle
Objects in a program should be replaceable with instances of their subtypes without altering the correctness of that program.
Interface segregation principle
Many client-specific interfaces are better than one general-purpose interface.
Dependency inversion principle
Depend upon abstractions, not concretions.
The package principles express similar concerns on a different level, for example (source):
Common Closure Principle
Classes that change together are packaged together.
Stable Dependencies Principle
Depend in the direction of stability.
Stable Abstractions Principle
Abstractness increases with stability.
We found that it’s very hard to apply the principles on a component level if the code doesn’t follow the equivalent principles on a class and method level. Well designed classes enable well designed components. Also, people familiar with applying the SOLID principles on a class level can easily scale these ideas up to the component level.
So if you’re having trouble establishing components that have strong boundaries, it may make sense to take a step back and make sure your organization gets better at software design on a scale of methods and classes first.
This is again mostly a matter of changing people’s behavior that requires motivation and ability. Motivation and ability can be increased by spreading awareness of the problems and approaches to solving them.
In the Ruby world, Sandi Metz is great at teaching these concepts. I recommend her books, and we’re lucky enough to have her teach workshops at Shopify repeatedly. She really gets people excited about software design.
Apply Tooling Deliberately
To accelerate our progress towards the modular monolith, we’ve made a few major changes to our tooling based on our experience so far.
Use Rails Engines
While we started out with a lot of custom code, our components evolved to look more and more like Rails Engines. We’re doubling down on engines going forward. They are the one modularity mechanism that comes with Rails out of the box. They have the familiar looks and features of Rails applications, but other than apps, we can run multiple engines in the same process. And should we make the decision to extract a component from the monolith, an engine is easily transformed into a standalone application.
Engines don’t fit the use case perfectly though. Some of the roughest edges are related to libraries and tooling assuming a Rails application structure, not the slightly different structure of an engine. Others relate to the fact that each engine can (and probably should) specify its own external gem dependencies, and we need a predictable way to unify them into one set of gems for the host application. Thankfully, there are quite a few resources out there from other projects encountering similar problems. Our own explorations have yielded promising results with multiple production applications currently using engines for modularity, and we’re using engines everywhere going forward.
Define and Enforce Contracts
Strong boundaries require explicit contracts. Contracts in code and documentation allow developers to use a component without reading its implementation, making the system feel smaller.
Initially, we built a hash schema validation library called Component::Schema based on dry-schema. It served us well for a while, but we ran into problems keeping up with breaking changes and runtime performance for checking more complex contracts.
In 2019, Stripe released their static Ruby type checker, Sorbet. Shopify was involved in its development before that release and has a team contributing to Sorbet, as we are using it heavily. Now it’s our go-to tool for expressing input and output contracts on component boundaries. Configured correctly, it has barely any runtime performance impact, it’s more stable, and it provides advanced features like interfaces.
This is what an entrypoint into a component looks like using Component::Schema:
And this is what that entrypoint looks like today, using Sorbet:
Perform Static Dependency Analysis
As Kirsten laid out in the original blog post on Componentization at Shopify, we initially built a call graph analysis tool we called Wedge. It logged all method calls during test suite execution on CI to detect calls between components.
We found the results produced were often not useful. Call graph logging produces a lot of data, so it’s hard to separate the signal from the noise. Sometimes it’s not even clear which component a call is from or to. Consider a method defined in component A which is inherited by a class in component B. If this method is making a call to component C, which component is the call coming from? Also, because this analysis depended on the full test suite with added instrumentation, it took over an hour to run, which doesn’t make for a useful feedback cycle.
So, we developed a new tool called Packwerk to analyze static constant references. For example, the line Shop.first, contains a static reference to Shop and a method call to a method on that class that’s called first. Packwerk only analyzes the static constant reference to Shop. There’s less ambiguity in static references, and because they’re always explicitly introduced by developers, highlighting them is more actionable. Packwerk runs a full analysis on our largest codebase in a few minutes, so we’re able to integrate it with our Pull Request workflow. This allows us to reject changes that break the dependency graph or component encapsulation before they get merged into our main branch.
We’re planning to make Packwerk open source soon. Stay tuned!
Decide to Prioritize Ownership or Boundaries
There are two major ways to partition an existing monolith and create components from a big ball of mud. In my experience, all large architecture changes end up in an incomplete state. Maybe that’s a pessimistic view, but my experience tells me that the temporary incomplete state will at least last longer than you expect. So choose an approach based on which intermediary state is most useful for your specific situation.
One option is to draw lines through the monolith based on some vision of the future and strengthen those lines over time into full fledged boundaries. The other option is to spin off parts of it into tiny units with strong boundaries and then transition responsibilities over iteratively, growing the components over time.
For our main monolith, we took the first approach; our vision was guided by the ideas of Domain Driven Design. We defined components as implementations of subdomains of the domain of commerce, and moved the files into corresponding folders. The main advantage is that even though we’re not finished building out the boundaries, responsibilities are roughly grouped together, and every file has a stewardship team assigned. The disadvantage is that almost no component has a complete, strong boundary yet, because with the components containing large amounts of legacy code, it’s a huge amount of work to establish these. This vision of the future approach is good if well-defined ownership and a clearly visible partition of the app are most important for you—which they were for us because of the huge number of people working on the codebase.
On other large apps within Shopify, we’ve tried out the second approach. The advantage is that large parts of the codebase are in isolated and clean components. This creates good examples for people to work towards. The disadvantage of this approach is that we still have a considerable sized ball of mud within the app that has no structure whatsoever. This spin-off approach is good if clean boundaries are the priority for you.
What We’re Building Right Now
While feature development on the monolith is going on as fast as ever, many developers are making things more modular at the same time. We see an increase of people in a position to do this, and the number of good examples around the codebase is expanding.
We currently have 37 components in our main monolith, each with public entrypoints covering large parts of its responsibilities. Packwerk is used on about a third of the components to restrict their dependencies and protect the privacy of their internal implementation. We’re working on making Packwerk enticing enough that all components will adopt it.
Through increased adoption we’re progressively enforcing properties of the dependency graph. Total acyclicity is the long term goal, but the more edges we can remove from the graph in the short term the easier the system will be to reason about.
We have a few other monolithic apps going through similar processes of componentization right now; some with the goal of splitting into separate services long term, some aiming for the modular monolith. We are very deliberate about when to split functionality out into separate services, and we only do it for good reasons. That’s because splitting a single monolithic application into a distributed system of services increases the overall complexity considerably.
For example, we split out storefront rendering because it’s a read-only use case with very high throughput and it makes sense for us to scale and distribute it separately from the interface that our merchants use to manage their stores. Credit card vaulting is a separate service because it processes sensitive data that shouldn’t flow through other parts of the system.
In addition, we’re preparing to have all new Rails applications at Shopify componentized by default. The idea is to generate multiple separately tested engines out of the box when creating a Rails app, removing the top level app folder and setting up developers for a modular future from the start.
At the same time, we’re looking into some of the patterns necessary to unblock further adoption of Packwerk. First and foremost that means making the dependency graph easy to clean up. We want to encourage inversion of control and more generally dependency inversion, which will probably lead us to use a publish/subscribe mechanism instead of straightforward method calls in many cases.
The second big blocker is efficiently querying data across components without coupling them too tightly. The most interesting problems in this area are
- Our GraphQL API exposes a partially circular graph to external consumers while we’d like the implementation in the components to be acyclic.
- Our GraphQL query execution and ElasticSearch reindexing currently heavily rely on Active Record features, which defeats the “public interface, private implementation” idea.
The long term vision is to have separate, isolated test suites for most of the components of our main monolith.
Last But Not Least
I want to give a shout out to Josh Abernathy, Bryana Knight, Matt Todd, Matthew Clark, Mike Chlipala and Jakob Class at Github. This blog post is based on, and indirectly the result of a conversation I had with them. Thank you!
Anita Clarke, Edward Ocampo-Gooding, Gannon McGibbon, Jason Gedge, Martin LaRochelle, and Keyfer Mathewson contributed super valuable feedback on this article. Thank you BJ Fogg for the behavior model and use of your image.
If you’re interested in the kinds of challenges I described, you should join me at Shopify!
Further Reading
- Kelly Sutton’s blog post How to Break Apart a Rails Monolith
- The Modular Monolith: Rails Architecture | by Dan Manges
- Rails conf talk: Between monoliths and microservices - by Vladimir Dementyev
- Book: Component-Based Rails Applications
- Sorbet, static type checker for Ruby
- Collection of resources about modular Rails applications
- Fogg Behavior Model
Definitions