
Using Server Sent Events to Simplify Real-time Streaming at Scale
When building any kind of real-time data application, trying to figure out how to send messages from the server to the client (or vice versa) is a big part of the equation. Over the years, various communication models have popped up to handle server-to-client communication, including Server Sent Events (SSE).
SSE is a unidirectional server push technology that enables a web client to receive automatic updates from a server via an HTTP connection. With SSE data delivery is quick and simple because there’s no periodic polling, so there’s no need to temporarily stage data.
This was a perfect addition to a real-time data visualization product Shopify ships every year—our Black Friday Cyber Monday (BFCM) Live Map.
Our 2021 Live Map system was complex and used a polling communication model that wasn’t well suited. While this system had 100 percent uptime, it wasn't without its bottlenecks. We knew we could improve performance and data latency.
Below, we’ll walk through how we implemented an SSE server to simplify our BFCM Live Map architecture and improve data latency. We’ll discuss choosing the right communication model for your use case, the benefits of SSE, and code examples for how to implement a scalable SSE server that’s load-balanced with Nginx in Golang.
Choosing a Real-time Communication Model
First, let’s discuss choosing how to send messages. When it comes to real-time data streaming, there are three communication models:
- Push: This is the most real-time model. The client opens a connection to the server and that connection remains open. The server pushes messages and the client waits for those messages. The server manages a registry of connected clients to push data to. The scalability is directly related to the scalability of this registry.
- Polling: The client makes a request to the server and gets a response immediately, whether there's a message or not. This model can waste bandwidth and resources when there are no new messages. While this model is the easiest to implement, it doesn’t scale well.
- Long polling: This is a combination of the two models above. The client makes a request to the server, but the connection is kept open until a response with data is returned. Once a response with new data is returned, the connection is closed.
No model is better than the other, it really depends on the use case.
Our use case is the Shopify BFCM Live Map, a web user interface that processes and visualizes real-time sales made by millions of Shopify merchants over the BFCM weekend. The data we’re visualizing includes:
- Total sales per minute
- Total number of orders per minute
- Total carbon offset per minute
- Total shipping distance per minute
- Total number of unique shoppers per minute
- A list of latest shipping orders
- Trending products
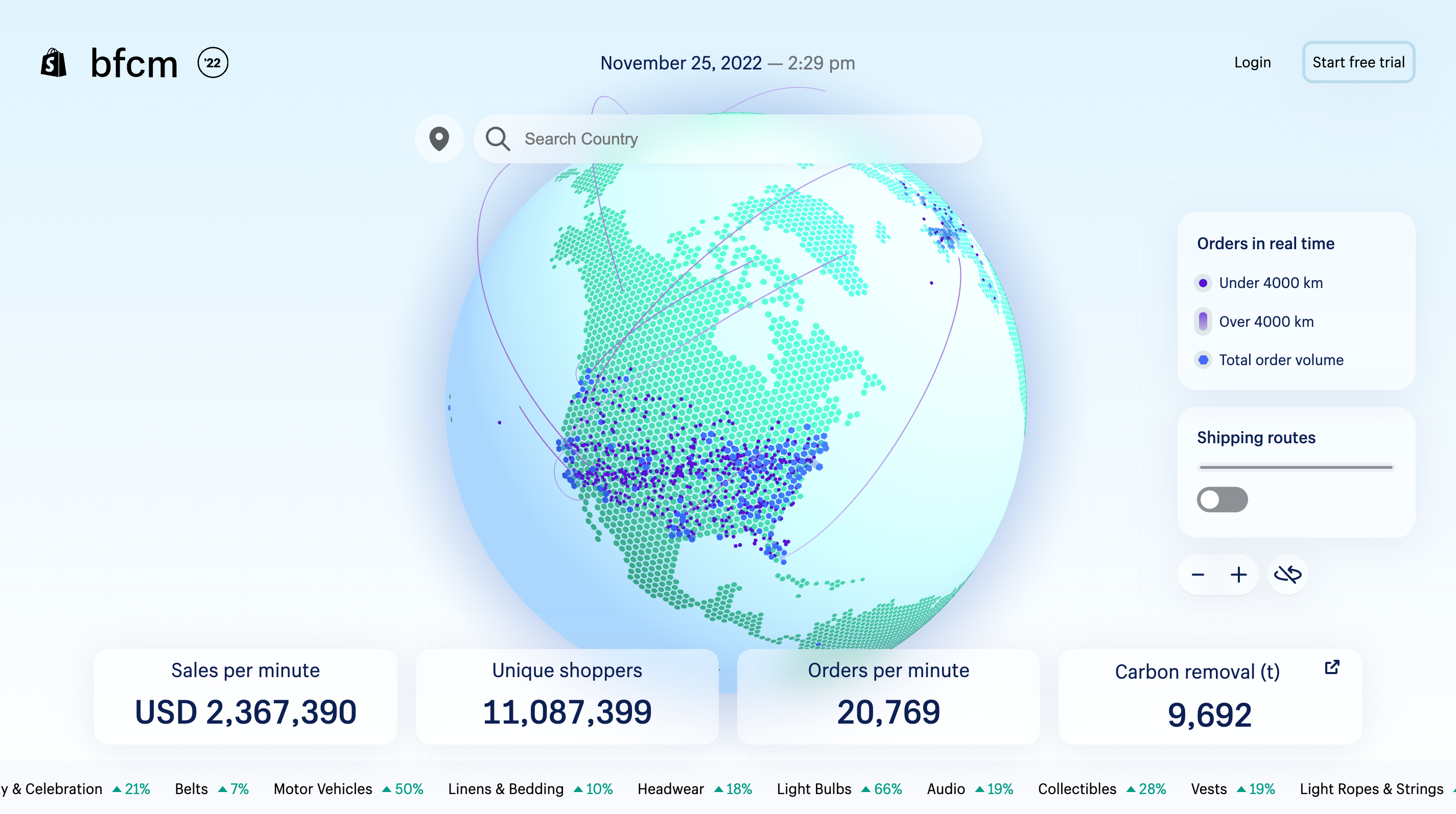
BFCM is the biggest data moment of the year for Shopify, so streaming real-time data to the Live Map is a complicated feat. Our platform is handling millions of orders from our merchants. To put that scale into perspective, during BFCM 2021 we saw 323 billion rows of data ingested by our ingestion service.
For the BFCM Live Map to be successful, it requires a scalable and reliable pipeline that provides accurate, real-time data in seconds. A crucial part of that pipeline is our server-to-client communication model. We need something that can handle both the volume of data being delivered, and the load of thousands of people concurrently connecting to the server. And it needs to do all of this quickly.
Our 2021 BFCM Live Map delivered data to a presentation layer via WebSocket. The presentation layer then deposited data in a mailbox system for the web client to periodically poll, taking (at minimum) 10 seconds. In practice, this worked but the data had to travel a long path of components to be delivered to the client.
Data was provided by a multi-component backend system consisting of a Golang based application (Cricket) using a Redis server and a MySQL database. The Live Map’s data pipeline consisted of a multi-region, multi-job Apache Flink based application. Flink processed source data from Apache Kafka topics and Google Cloud Storage (GCS) parquet-file enrichment data to produce into other Kafka topics for Cricket to consume.

While this got the job done, the complex architecture caused bottlenecks in performance. In the case of our trending products data visualization, it could take minutes for changes to become available to the client. We needed to simplify in order to improve our data latency.
As we approached this simplification, we knew we wanted to deprecate Cricket and replace it with a Flink-based data pipeline. We’ve been investing in Flink over the past couple of years, and even built our streaming platform on top of it—we call it Trickle. We knew we could leverage these existing engineering capabilities and infrastructure to streamline our pipeline.
With our data pipeline figured out, we needed to decide on how to deliver the data to the client. We took a look at how we were using WebSocket and realized it wasn’t the best tool for our use case.
Server Sent Events Versus WebSocket
WebSocket provides a bidirectional communication channel over a single TCP connection. This is great to use if you’re building something like a chat app, because both the client and the server can send and receive messages across the channel. But, for our use case, we didn’t need a bidirectional communication channel.
The BFCM Live Map is a data visualization product so we only need the server to deliver data to the client. If we continued to use WebSocket it wouldn’t be the most streamlined solution. SSE on the other hand is a better fit for our use case. If we went with SSE, we’d be able to implement:
- A secure uni-directional push: The connection stream is coming from the server and is read-only.
- A connection that uses ubiquitously familiar HTTP requests: This is a benefit for us because we were already using a ubiquitously familiar HTTP protocol, so we wouldn’t need to implement a special esoteric protocol.
- Automatic reconnection: If there's a loss of connection, reconnection is automatically retried after a certain amount of time.
But most importantly, SSE would allow us to remove the process of retrieving, processing, and storing data on the presentation layer for the purpose of client polling. With SSE, we would be able to push the data as soon as it becomes available. There would be no more polls and reads, so no more delay. This, paired with a new streamlined pipeline, would simplify our architecture, scale with peak BFCM volumes and improve our data latency.
With this in mind, we decided to implement SSE as our communication model for our 2022 Live Map. Here’s how we did it.
Implementing SSE in Golang
We implemented an SSE server in Golang that subscribes to Kafka topics and pushes the data to all registered clients’ SSE connections as soon as it’s available.

A real-time streaming Flink data pipeline processes raw Shopify merchant sales data from Kafka topics. It also processes periodically-updated product classification enrichment data on GCS in the form of compressed Apache Parquet files. These are then computed into our sales and trending product data respectively and published into Kafka topics.
Here’s a code snippet of how the server registers an SSE connection:
| func (sseServer *SSEServer) handleConnection(rw http.ResponseWriter, req *http.Request) { | |
| flusher, ok := rw.(http.Flusher) | |
| if !ok { | |
| http.Error(rw, "Streaming unsupported!", http.StatusInternalServerError) | |
| return | |
| } | |
| auth := req.Header.Get("Authorization") | |
| //handling authorization header | |
| ..... | |
| rw.Header().Set("Content-Type", "text/event-stream") | |
| rw.Header().Set("Cache-Control", "no-cache") | |
| rw.Header().Set("Connection", "keep-alive") | |
| rw.Header().Set("X-Accel-Buffering", "no") | |
| rw.Header().Set("Access-Control-Allow-Origin", "*") | |
| rw.Header().Set("Access-Control-Allow-Methods", "POST, GET, OPTIONS") | |
| rw.Header().Set("Access-Control-Allow-Headers", "Content-Type, authorization, X-Requested-With") | |
| // register connection message channel | |
| messageChan := make(chan []byte) | |
| // signal the Server of a new client connection | |
| sseServer.NewClientsChannel <- messageChan | |
| //keeping the connection alive with keep-alive protocol | |
| keepAliveTickler := time.NewTicker(15 * time.Second) | |
| keepAliveMsg := ":keepalive\n" | |
| notify := req.Context().Done() | |
| //listen to signal to close and unregister | |
| go func() { | |
| <-notify | |
| sseServer.ClosingClientsChannel <- messageChan | |
| keepaliveTickler.Stop() | |
| }() | |
| defer func() { | |
| sseServer.ClosingClientsChannel <- messageChan | |
| }() | |
| for { | |
| select { | |
| //receiving a message from the Kafka channel. | |
| case kafkaEvent := <-messageChan: | |
| // Write to the ResponseWriter in SSE compatible format | |
| fmt.Fprintf(rw, "data: %s\n\n", kafkaEvent) | |
| flusher.Flush() | |
| case <-keepAliveTickler.C: | |
| fmt.Fprintf(rw, keepAliveMsg) | |
| flusher.Flush() | |
| } | |
| } | |
| } |
Subscribing to the SSE endpoint is simple with the EventSource interface. Typically, client code creates a native EventSource object and registers an event listener on the object. The event is available in the callback function:
| eventSource = new EventSource("http://localhost:8081/events") | |
| eventSource.addEventListener('message', e => { | |
| var data = JSON.parse(e.data); | |
| console.log(data); | |
| }); |
When it came to integrating the SSE server to our frontend UI, the UI application was expected to subscribe to an authenticated SSE server endpoint to receive data. Data being pushed from the server to client is publicly accessible during BFCM, but the authentication enables us to control access when the site is no longer public. Pre-generated JWT tokens are provided to the client by the server that hosts the client for the subscription. We used the open-sourced EventSourcePolyfill implementation to pass an authorization header to the request:
| eventSource = new EventSourcePolyfill("http://localhost:8081/events", { | |
| headers: { | |
| 'Authorization': "bearer xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" | |
| } | |
| }); | |
| eventSource.addEventListener('message', e => { | |
| var data = JSON.parse(e.data); | |
| //process data | |
| }); |
Once subscribed, data is pushed to the client as it becomes available. Data is consistent with the SSE format, with the payload being a JSON parsable by the client.
Ensuring SSE Can Handle Load
Our 2021 system struggled under a large number of requests from user sessions at peak BFCM volume due to the message bus bottleneck. We needed to ensure our SSE server could handle our expected 2022 volume.
With this in mind, we built our SSE server to be horizontally scalable with the cluster of VMs sitting behind Shopify’s NGINX load-balancers. As the load increases or decreases, we can elastically expand and reduce our cluster size by adding or removing pods. However, it was essential that we determined the limit of each pod so that we could plan our cluster accordingly.
One of the challenges of operating an SSE server is determining how the server will operate under load and handle concurrent connections. Connections to the client are maintained by the server so that it knows which ones are active, and thus which ones to push data to. This SSE connection is implemented by the browser, including the retry logic. It wouldn’t be practical to open tens of thousands of true browser SSE connections. So, we need to simulate a high volume of connections in a load test to determine how many concurrent users one single server pod can handle. By doing this, we can identify how to scale out the cluster appropriately.
We opted to build a simple Java client that can initiate a configurable amount of SSE connections to the server. This Java application is bundled into a runnable Jar that can be distributed to multiple VMs in different regions to simulate the expected number of connections. We leveraged the open-sourced okhttp-eventsource library to implement this Java client.
Here’s the main code for this Java client:
| public static void process(String endpoint, String bearerToken, int numberOfSessions, long pauseTimeMs, int sessionLengthMins) throws Exception{ | |
| EventHandler handler =new EventHandler() { | |
| @Override | |
| public void onOpen() throws Exception { | |
| System.out.println("Open "); | |
| } | |
| @Override | |
| public void onClosed() throws Exception { | |
| System.out.println("closed "); | |
| } | |
| @Override | |
| public void onMessage(String s, MessageEvent messageEvent) throws Exception { | |
| System.out.println("message: " + messageEvent.getData()); | |
| } | |
| @Override | |
| public void onComment(String s) throws Exception { | |
| System.out.println("comment: "+s); | |
| } | |
| @Override | |
| public void onError(Throwable throwable) { | |
| throwable.printStackTrace(); | |
| } | |
| }; | |
| EventSource.Builder builder = new EventSource.Builder(handler, URI.create(endpoint)).headers(Headers.of("Authorization","bearer "+bearerToken)); | |
| for(int i = 0; i< numberOfSessions; i++) { | |
| TimeUnit.MILLISECONDS.sleep(pauseTimeMs); | |
| Thread t = new Thread(new Runnable() { | |
| @Override | |
| public void run() { | |
| try (EventSource eventSource = builder.build()) { | |
| eventSource.start(); | |
| TimeUnit.MINUTES.sleep(sessionLengthMins); | |
| }catch(Exception ex) { | |
| ex.printStackTrace(); | |
| } | |
| } | |
| }); | |
| t.setDaemon(false); | |
| t.start(); | |
| } | |
| } |
Did SSE Perform Under Pressure?
With another successful BFCM in the bag, we can confidently say that implementing SSE in our new streamlined pipeline was the right move. Our BFCM Live Map saw 100 percent uptime. As for data latency in terms of SSE, data was delivered to clients within milliseconds of its availability. This was much improved from the minimum 10 second poll from our 2021 system. Overall, including the data processing in our Flink data pipeline, data was visualized on the BFCM’s Live Map UI within 21 seconds of its creation time.
We hope you enjoyed this behind the scenes look at the 2022 BFCM Live Map and learned some tips and tricks along the way. Remember, when it comes to choosing a communication model for your real-time data product, keep it simple and use the tool best suited for your use case.
Bao is a Senior Staff Data Engineer who works on the Core Optimize Data team. He's interested in large-scale software system architecture and development, big data technologies and building robust, high performance data pipelines.
Our platform handled record-breaking sales over BFCM and commerce isn't slowing down. Want to help us scale and make commerce better for everyone? Join our team.