
Read Consistency with Database Replicas
At Shopify, we’ve long used database replication for redundancy and failure recovery, but only fairly recently started to explore the potential of replicas as an alternative read-only data source for applications. Using read replicas holds the promise of enhanced performance for read-heavy applications, while alleviating pressure on primary servers that are needed for time-sensitive read/write operations.
There's one unavoidable factor that can cause problems with this approach: replication lag. In other words, applications reading from replicas might be reading stale data—maybe seconds or even minutes old. Depending on the specific needs of the application, this isn’t necessarily a problem. A query may return data from a lagging replica, but any application using replicated data has to accept that it will be somewhat out of date; it’s all a matter of degree. However, this assumes that the reads in question are atomic operations.
In contrast, consider a case where related pieces of data are assembled from the results of multiple queries. If these queries are routed to various read replicas with differing amounts of replication lag and the data changes in midstream, the results could be unpredictable.
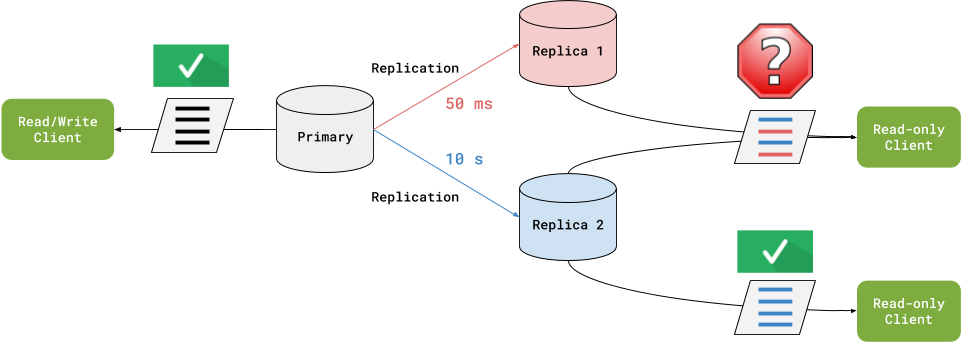
For example, a row returned by an initial query could be absent from a related table if the second query hits a more lagging replica. Obviously, this kind of situation could negatively impact the user experience and, if these mangled datasets are used to inform future writes, then we’re really in trouble. In this post, I’ll show you the solution the Database Connection Management team at Shopify chose to solve variable lag and how we solved the issues we ran into.
Tight Consistency
One way out of variable lag is by enforcing tight consistency, meaning that all replicas are guaranteed to be up to date with the primary server before any other operations are allowed. This solution is expensive and negates the performance benefits of using replicas. Although we can still lighten the load on the primary server, it’s at the cost of delayed reads from replicas.
Causal Consistency
Another approach we considered (and even began to implement) is causal consistency based on global transaction identifier (GTID). This means that each transaction in the primary server has a GTID associated with it, and this GTID is preserved as data is replicated. This allows requests to be made conditional upon the presence of a certain GTID in the replica, so we can ensure replicated data is at least up to date with a certain known state in the primary server (or a replica), based on a previous write (or read) that the application has performed. This isn’t the absolute consistency provided by tight consistency, but for practical purposes it can be equivalent.
The main disadvantage to this approach is the need to implement software running on each replica which would report its current GTID back to the proxy so that it can make the appropriate server selection based on the desired minimum GTID. Ultimately, we decided that our use cases didn’t require this level of guarantee, and that the added level of complexity was unnecessary.
Our Solution to Read Consistency
Other models of consistency in replicated data necessarily involve some kind of compromise. In our case, we settled on a form of monotonic read consistency: successive reads will follow a consistent timeline, though not necessarily reading the latest data in real time. The most direct way to ensure this is for any series of related reads to be routed to the same server, so successive reads will always represent the state of the primary server at the same time or later, compared to previous reads in that series.

In order to simplify implementation and avoid unnecessary overhead, we wanted to offer this functionality on an opt-in basis, while at the same time avoiding any need for applications to be aware of database topology and manage their own use of read replicas. To see how we did this, let’s first take a step back.
Application access to our MySQL database servers is through a proxy layer provided by ProxySQL using the concept of hostgroups: essentially pools of interchangeable servers which look like a single data source from the application’s point of view.

When a client application connects with a user identity assigned to a given hostgroup, the proxy routes its individual requests to any randomly selected server within that hostgroup. (This is somewhat oversimplified in that ProxySQL incorporates considerations of latency, load balancing, and such into its selection algorithm, but for purposes of this discussion we can consider the selection process to be random). In order to provide read consistency, we modified this server selection algorithm in our fork of ProxySQL.
Any application which requires read consistency within a series of requests can supply a unique identifier common to those requests. This identifier is passed within query comments as a key-value pair:
/* consistent_read_id:<some unique ID> */ SELECT <fields> FROM <table>
The ID we use to identify requests is always a universally unique identifier (UUID) representing a job or any other series of related requests. This consistent_read_id forms the basis for a pseudorandom but repeatable index into the list of servers that replaces the default random indexing taking place in the absence of this identifier. Let’s see how.
First, a hashing algorithm is applied to the consistent_read_id to yield an integer value. We calculate the modulo of this number and the number of servers that becomes our pseudorandom index into the list of available servers. Repeated application of this algorithm yields the same pseudorandom result, thus maintaining read consistency over a series of requests specifying the same consistent_read_id. This explanation is simplified in that it ignores the server weighting which is configurable in ProxySQL. Here’s what an example looks like, including the server weighting:

consistent_read_id is used to generate a hash that yields an index into a weighted list of servers. In this example, every time we receive this particular consistent_ read_ id, server 1 will be selected.A Couple of Bumps in the Road
I’ve covered the basics of our consistent-read algorithm, but there were a couple of issues to be addressed before the team got it working perfectly.
The first one surfaced during code review and relates to situations where a server becomes unavailable between successive consistent read requests. If the unavailable server is the one that was previously selected (and therefore would’ve been selected again), a data inconsistency is possible—this is a built-in limitation of our approach. However, even if the unavailable server isn’t the one that would’ve been selected, applying the selection algorithm directly to the list of available servers (as ProxySQL does with random server selection) could also lead to inconsistency, but in this case unnecessarily. To address this issue, we index into the entire list of configured servers in the host group first, then disqualify the selected server and reselect if necessary. This way, the outcome is affected only if the selected server is down, rather than having the indexing potentially affected for others in the list. Discussion of this issue in a different context can be found on ebrary.net.

The second issue was discovered as an intermittent bug that led to inconsistent reads in a small percentage of cases. It turned out that ProxySQL was doing an additional round of load balancing after initial server selection. For example, in a case where the target server weighting was 1:1 and the actual distribution of server connections drifted to 3:1, any request would be forcibly rerouted to the underweighted server, overriding our hash-based server selection. By disabling the additional rebalancing in cases of consistent-read requests, these sneaky inconsistencies were eliminated.
Currently, we're evaluating strategies for incorporating flexible use of replication lag measurements as a tuneable factor that we can use to modify our approach to read consistency. Hopefully, this feature will continue to appeal to our application developers and improve database performance for everyone.
Our approach to consistent reads has the advantage of relative simplicity and low overhead. Its main drawback is that server outages (especially intermittent ones) will tend to introduce read inconsistencies that may be difficult to detect. If your application is tolerant of occasional failures in read consistency, this hash-based approach to implementing monotonic read consistency may be right for you. On the other hand, if your consistency requirements are more strict, GTID-based causal consistency may be worth exploring. For more information, see this blog post on the ProxySQL website.
Thomas has been a software developer, a professional actor, a personal trainer, and a software developer again. Currently, his work with the Database Connection Management team at Shopify keeps him learning and growing every day.
We're always on the lookout for talent and we’d love to hear from you. Visit our Engineering career page to find out about our open positions.