
To do this, we considered two metrics of highest importance:
- How often were our predictions correct? To answer this question, we looked at the precision, recall, and accuracy of the model. This should be very familiar to anyone who has prior experience with classification machine learning models. For the sake of simplicity let us call this set of metrics , “accuracy”. These metrics are calculated using a hold out set to ensure an unbiased measurement.
- How often do we provide a prediction? Our existing model filters out predictions below a certain confidence thresholds to ensure we were only providing predictions that we were confident about. So, we defined a metric called “coverage”: the ratio of the number of products with a prediction and the total number of products.
In addition to these two metrics, we also care about how these predictions are consumed and if we’re providing the right access patterns and SLA’s to satisfy all use cases. As an example, we might want to provide low latency real time predictions to our consumers.
After evaluating our model against these metrics and taking into account the various data products we were looking to build, we decided to build a new model to improve our performance. As we approached the problem, we reminded ourselves of the blind spots of the existing model. These included things such as only using textual features for prediction and the ability to only understand products in the english language.
In this post, we’ll discuss how we evolved and modernized our product categorization model that increased our leaf precision by 8% while doubling our coverage. We’ll dive into the challenges of solving this problem at scale and the technical trade-offs we made along the way. Finally we’ll describe a product that’s currently being used by multiple internal teams and our partner ecosystems to build derivative data products.
Why Is Product Categorization Important?
Before we discuss the model, let’s recap why product categorization is an important problem to solve.
Merchants sell a variety of products on our platform, and these products are sold across different sales channels. We believe that the key to building the best products for our merchants is to understand what they’re selling. For example, by classifying all the products our merchants sell into a standard set of categories, we can build features like better search and discovery across all channels and personalized insights to support merchants’ marketing efforts.
Our current categorization model uses the Google Product Taxonomy (GPT). The GPT is a list of over 5,500 categories that help us organize products. Unlike a traditional flat list of categories or labels that’s common to most classification problems, the GPT has a hierarchical tree structure. Both the sheer number of categories in the taxonomy and the complex structure and relationship between the different classes make this a hard problem to model and solve.

The Model
Before we could dive into creating our improved model, we had to take into account what we had to work with by exploring the product features available to us. Below is an example of the product admin page you would see in the backend of a Shopify merchant’s store:
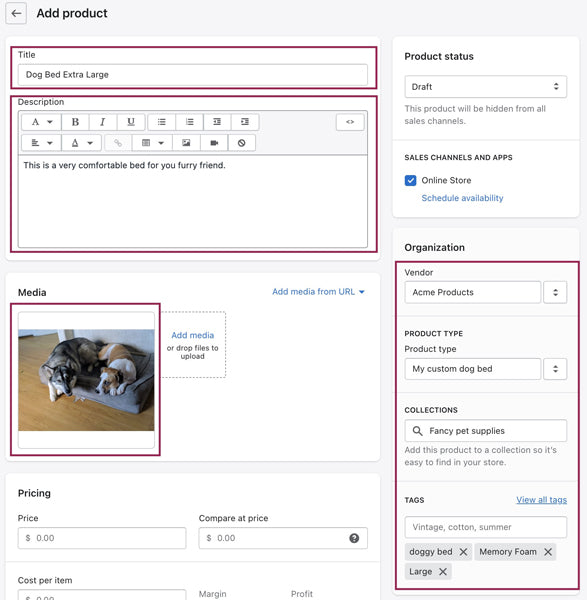
The image above shows the product admin page in the Shopify admin. We have highlighted the features that can help us identify what the product is. These include the title, description vendor, product type collection, tags and the product images.
Clearly we have a few features that can help us identify what the product is, but nothing in a structured format. For example, multiple merchants selling the same product can use different values for Product Type. While this provides a lot of flexibility for the merchant to organize their inventory internally, it creates a harder problem in categorizing and indexing these products across stores.
Broadly speaking we have two types of features available to us:
|
Text Features |
|
|
Visual Features |
|
These are the features we worked with to categorize the products.
Feature Vectorization
To start off, we had to choose what kind of vectorization approaches our features need since both text and image features can’t be used by most machine learning models in their raw state. After a lot of experimentation, we moved forward with transfer learning using neural networks. We used pre-trained image and text models to convert our raw features into embeddings to be further used for our hierarchical classification. This approach provided us with flexibility to incorporate several principles that we’ll discuss in detail in the next section.
We horse raced several pre-trained models to decide which models to use for image and text embeddings. The parameters to consider were both model performance and computational cost. As we balanced out these two parameters, we settled on the choice of:
- Multi-Lingual BERT for text
- MobileNet-V2 for images
Model Architecture
As explained in our previous post, categorizing hierarchical classification problems presents us with additional challenges beyond a flat multi-class problem. We had two lessons from our previous attempts at solving this problem:
- Preserving the multi-class nature of this problem is extremely beneficial in making predictions. For example: Level 1 in the taxonomy has 21 different class labels compared to more than 500 labels at Level 3.
- Learning parent nodes helps in predicting the child node. For example, if we look back at the image in our example of the Shopify product admin, it’s easier to predict the product as “Dog Beds”, if we’ve already predicted it as belonging to “Dog Supplies”.
So, we went about framing the problem as a multi-task, multi-class classification problem in order to incorporate these learnings into our model.
- Multi-Task: Each level of the taxonomy was treated as a separate classification problem and the output of each layer would be fed back into the next model to make the next level prediction.
- Multi-Class: Each level in the taxonomy contains a varying number of classes to choose from, so each task became a single multi-class classification problem.

The above image illustrates the approach we took to incorporate these lessons. As mentioned previously, we use pre-trained models to embed the raw text and image features and then feed the embeddings into multiple hidden layers before having a multi-class output layer for the Level 1 prediction. We then take the output from this layer along with the original embeddings and feed it into subsequent hidden layers to predict Level 2 output. We continue this feedback loop all the way until Level 7.
Some important points to note:
- We have a total of seven output layers corresponding to the seven levels of the taxonomy. Each of these output layers has its own loss function associated with it.
- During the forward pass of the model, parent nodes influence the outputs of child nodes.
- During backpropagation, the losses of all seven output layers are combined in a weighted fashion to arrive at a single loss value that’s used to calculate the gradients. This means that lower level performances can influence the weights of higher level layers and nudge the model in the right direction.
- Although we feed parent node prediction to child node prediction tasks in order to influence those predictions, we don’t impose any hard constraints that the child node prediction should strictly be a child of the previous level prediction. As an example the model is allowed to predict Level 2 as “Pet Supplies” even if it predicted Level 1 as “Arts & Entertainment”. We allow this during training so that accurate predictions at child nodes can nudge wrong predictions at the parent node in the right direction. We’ll revisit this point during the inference stage in a subsequent section.
- We can handle imbalance in classes using class weights during the training stage. The dataset we have is highly imbalanced. This makes it difficult for us to train a classifier that generalizes. Adding class weights enables us to mitigate the effects of the class imbalance. By providing class weights we’re able to penalize errors in predicting classes that have fewer samples compared thereby overcoming the lack of observations in those classes.
Model Training
One of the benefits of Shopify's scale is the availability of large datasets to build great data products that benefit our merchants and their buyers. For product categorization, we have collected hundreds of millions of observations to learn from. But this also comes with its own set of challenges! The model we described above turns out to be massive in complexity. It ends up having over 250 million parameters. Add to this the size of our dataset, training this model in a reasonable amount of time is a challenging task. Training this model using a single machine can run into multiple weeks even with GPU utilization. We needed to bring down training time while also not sacrificing the model performance.
We decided to go with a data parallelization approach to solve this training problem. It would enable us to speed up the training process by chunking up the training dataset and using one machine per chunk to train the model. The model was built and trained using distributed Tensorflow using multiple workers and GPUs on Google Cloud Platform. We performed multiple optimizations to ensure that we utilized these resources as efficiently as possible.
Model Inference and Predictions
As described in the model architecture section, we don’t constrain the model to strictly follow the hierarchy during training. While this works during training, we can’t allow such behavior during inference time or we jeopardize providing a reliable and smooth experience for our consumers. To solve this problem, we incorporate additional logic during the inference step. The steps during predictions are
- Make raw predictions from the trained model. This will return seven arrays of confidence scores. Each array represents one level of the taxonomy.
- Choose the category that has the highest confidence score at Level 1 and designate that as the Level 1 Prediction.
- Collect all the immediate descendants of the Level 1 prediction. From among these, choose the child that has the highest confidence score and designate this as the Level 2 prediction.
- Continue this process until we reach the Level 7 prediction.
We perform the above logic as Tensorflow operations and build a Keras subclass model to combine these operations with the trained model. This allows us to have a single Tensorflow model object that contains all the logic used in both batch and online inference.

The image above illustrates how we build a Keras subclass model to take the raw trained Keras functional model and attach it to a downstream Tensorflow graph to do the recursive prediction.
Metrics and Performance
We collected a suite of different metrics to measure the performance of a hierarchical classification model. These include:
- Hierarchical accuracy
- Hierarchical precision
- Hierarchical recall
- Hierarchical F1
- Coverage
In addition to gains in all the metrics listed above, the new model classifies products in multiple languages and isn’t limited to only products with English text, which is critical for us as we further Shopify's mission of making commerce better for everyone around the world.
In order to ensure only the highest quality predictions are surfaced, we impose varying thresholds on the confidence scores at different levels to filter out low confidence predictions. This means not all products have predictions at every level.
An example of this is shown in the image below:

The image above illustrates how the photo of the dog bed results in four levels of predictions. The first three levels all have a high confidence score and will be exposed. The fourth level prediction has a low confidence score and this prediction won’t be exposed.
In this example, we don’t expose anything beyond the third level of predictions since the fourth level doesn’t satisfy our minimum confidence requirement.
One thing we’ve learned during this process was how to tune the model so that these different metrics were balanced in an optimal way. We could, for example, achieve a higher hierarchical precision at the cost of lower coverage. These are hard decisions to make and would need us to understand our business use case and the priorities to make these decisions. We can’t emphasize enough how vital it is for us to focus on the business use cases and the merchant experience in order to guide us. We optimized towards reducing negative merchant experience and friction. While metrics are a great indication of model performance, we also conducted spot checks and manual QA on our predictions to identify areas of concern.
An example is how we paid close attention to model performance on items that belonged to sensitive categories like “Religious and Ceremonial”. While overall metrics might look good, they can also mask model performance in small pockets of the taxonomy that can cause a lot of merchant friction. We manually tuned thresholds for confidences to ensure high performance in these sensitive areas. We encourage the reader to also adopt this practice in rolling out any machine learning powered consumer facing data product.
Where Do We Go From Here?
The upgrade from the previous model gave us a boost in both precision and coverage. At a high level, we were able to increase precision by eight percent while also almost doubling the coverage. We have more accurate predictions for a lot more products. While we improved the model and delivered a robust product to benefit our merchants, we believe we can further improve it. Some of the areas of improvements include:
- Data Quality: While we do have a massive rich dataset of labelled products, it does contain high imbalance. While we can address imbalance in the dataset using a variety of well known techniques like class weights and over/undersampling, we also believe we should be collecting fresh data points in areas where we currently don’t have enough. As Shopify grows, we notice that the products that our merchants sell get more and more diverse by the day. This means we’ll need to keep collecting data in these new categories and sections of the taxonomy.
- Merchant Level Features: The current model focuses on product level features. While this is the most obvious place to start, there are also a lot of signals that don’t strictly belong at the individual product level but roll up to the merchant level that can help us make better predictions. A simple example of this is a hypothetical merchant called “Acme Shoe warehouse”. It looks clear that the name of this store strongly hints at what the product this store sells could be.
Kshetrajna Raghavan is a data scientist who works on Shopify's Commerce Algorithms team. He enjoys solving complex problems to help use machine learning at scale. He lives in the San Francisco Bay Area with his wife and two dogs. Connect with Kshetrajna on LinkedIn to chat.
If you’re passionate about solving complex problems at scale, and you’re eager to learn more, we're always hiring! Reach out to us or apply on our careers page.
Topics:
Join 446,005 entrepreneurs who already have a head start.
Get free online marketing tips and resources delivered directly to your inbox.
Thanks for subscribing
You’ll start receiving free tips and resources soon. In the meantime, start building your store with a free 14-day trial of Shopify.





