
Defining Churn Rate (no really, this actually requires an entire blog post)
By Steven H. Noble
If you go to three different analysts looking for a definition of "churn rate," they will all agree that it's an important metric and that the definition is self evident. Then they will go ahead and give you three different definitions. And as they share their definitions with each other they all have the same response: why is everyone else making this so complicated?
How can it be so confusing? All I want to know is how quickly my users are cancelling their service.
Unfortunately, churn rate is actually an extremely important metric. Why? To put it in modern startup terminology, churn rate is an ideal actionable (non-vanity) metric. As Eric Ries describes in his classic blog post, understanding your company metrics at a customer level is key to understanding the effects of your actions. It is your customer level metrics that will inform you if you are currently on a path to profitability, or if your current profits are sustainable. And at the heart of customer level metrics is churn rate: the measurement of the likelihood of your customer to become an ex-customer.
Let me take you through the recent stumbling process we went through at Shopify and share with you the definition we ended up with. (Or you can jump straight to the answer.)
The accountants' dream
As I say, a churn rate seems simple. Since it's just a rate all you need is a numerator and a denominator, right? So why not pick the obvious numerator and denominator.

The problem here is that the [number of churns over period] value is affected by the entire period but the [number of customers at beginning of period] value is a snapshot from the beginning of the period. This might not have much impact if new customers only make up a small percentage of your user base but for a company that's growing this can lead to some major misinterpretations.
Consider you are calculating your churn rate for July and August. Let's say in July you started with 10,000 customers, lost 500 of them (5% of 10,000), gained 5,000 but lost 125 of those (you only lose 2.5% of the 5,000 because you gain those 5,000 over the course of the month). Now in August you start with 14,375 customers and lost a similar amount of 719 (5% of 14,375), gained another 5,000 and again lost 125 of them. So July's churn rate would be 6.25% and August's would be 5.87%. That's a shift of 38 basis points for the exact same behaviour in both months (here the standard deviation is about 20~25 basis points depending on how you calculate it). You would have told yourself that your churn rate is improving when nothing has changed. Misreporting your performance is a bad problem to have.
And beyond that, what if July had been a dead month with only 100 new customers, 2 of which churned, and then August picked up again. Then July would have a churn rate of 5.02% and August would have a churn rate of 6.3%. This is because this definition of churn rate is directly influenced by the number of new customers you acquire. But the whole point of a churn rate is to understand churn behaviour normalized for growth and size.
The accountants' adjusted dream
Since we had a classic problem in financial analysis in our previous rate, let us try the classic solution.

Great, this seems to solve the problem of the number of new customers affecting our measurement of churn: according to this definition in either of the scenarios above we always have a churn rate of 5.1% (that is where July was dead or not). Our fluctuations due to artifacting has disappeared.
So let's go on and consider the next natural question: what is the churn rate for the quarter? Well, if we say September is like August and gains another 5,000 customers, 125 of which it loses, and it lost 927 of your original customers, you end up with 22,480 at the end of the month. So if you use this definition you end up with a churn rate for the quarter of 15.5%?! That's a pretty radical shift from 5.1%.
But of course I should calm down. My quarter has three months in it so I just have to divide my 15.5% by three, right? And I have a reasonable number of 5.2%. However, let's consider that dead July again where I only gained 100 customers. I still had a July, August, September churn rate of 5.1% but now my quarterly churn is 4.6%?!
This is because my formula has a cooked in assumption that the churns are evenly spread out. If your data breaks this assumption you will get results that no longer make sense. Unfortunately you can't insist your customers follow your assumptions so that your equations are satisfied (I'm just imagining telling a customer "I'm sorry, we're going to have to churn you today because we haven't had enough churns to satisfy our linearly distribution assumption").
A good ratio metric needs to be able to expand and shrink in the length of period that it measures. You want to be able to see how your current month churn rate compares to the churn rate of the quarter or the YTD churn rate. You also should be able to change your view to be able to see a weekly churn rate that provides better resolution but still with comparable values. And even a daily churn rate. (Of course the more narrow your window the more volatility you should expect.)
Even going from 28 days in February to 31 days in March is enough of an increase in days to create results that will suggest churn is increasing even though customer behaviour hasn't changed.
(As an aside I once suggested that we stop reporting figures for actual months and instead chop up the year into 30 day periods and only report figures for these 30 day Shopify months. I didn't really get an answer as much as a I got a look that said did we really just hire this guy? I needed to remind myself that analysis needs to work within the world that we are in if it is to be useful; not an idealized version of the world. The globe isn't a sphere. The market isn't efficient. And months aren't all 30 days.)
We also tried:

which basically has the same problems but to different degrees. Instead we had to let this dream die and consider alternatives.
The predictive modelers' fancy
From a predictive modeling background my priority was how can I define a churn rate so that it might be useful for making predictions. The most straight forward way to do this is to find a churn rate r so that if you have the number of customers for today n then r*n is a prediction for the number of customers that will have churned sometime in the next 30 days (this is actually not a very good way to make this sort of prediction). To do this you might take the weighted average of rate of people who churn within 30 days for every day in your period. That is:
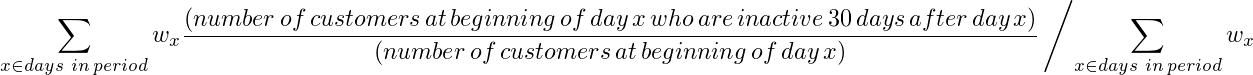
or

where the weights are

This seems to solve all of our past problems. If customer behaviour remains unchanged then this churn rate will remain consistent. And it can happily return a churn rate for a month, a week, or a day all in nice comparable numbers.
However, this number hindered by the fact that it is neither current or timely. By timely I mean that at the end of August the most recent churn rates you can report are for periods that end August 1st. You have to wait until the end of September before you can report August's churn rate. At worst you want to be able to report a month's rate only two or three days after the month ends. Maybe this is just a perception problem that can be solved by reporting July's churn rate for August; ie change the recognition date. This opens other problems and doesn't resolve the issue of not being current.
By current I mean that there are churn events that have occurred that can't be reflected in your most recent churn rate. It is possible for a surge in cancellations to not be captured in the churn rate until weeks later. This is a major problem. If your main measure for churn isn't able to notify you of a major change in churn behaviour shortly after the change then it is not performing one of its primary functions.
But really, these are all problems with the fact this metric makes it too hard to understand what is going on. That is when you say this is the churn rate for August 24th to the 31st one expects that this number is an aggregate of churn behaviour during that week. Instead, churn behaviour during that week and most of the month of August is reflected in that number. But only some of that churn behaviour from August. Which means it is very hard to understand how this number relates to when anything else is happening in your business. You get funky effects like churn rate dropping just before you put into practice a new retention strategy.
So while it is nice that this version of churn rate has some predictive utility it fails on so many other accounts that it no longer seems so fancy.
Where we ended up
Between these two ideas is where we ended up:

or

where the weights are

We've found that resolves all the issues we've had above: it's current, it's timely, it produces comparable results for different period lengths, and an increase or decrease in this churn rate reflects an actual change in churn behaviour for your measured period.
This isn't the best number to use to multiply your current customer count by to get an estimate of how many of your current customers will churn in the next 30 days. However, as demonstrated in a post over at Custora, this isn't a good practice anyhow.
What this metric is useful for is keeping track of changes in customer churn behaviour while giving a rough estimate of what percentage of your customers will leave in the next 30 days.
And finally, what makes this calculation actually something we can use is the fact that the components are all reconciliable numbers that we were already recording. While I am clearly a fan of rigor I believe that your final result should follow the 37signals advise of of "make it easy." All you have to know is how many customers you have each day and the number of cancellations for each day. Of course "customers" and "cancellations" are definitions that also need to be sorted out.
Epilogue
One thing that I did not mention but needs to be kept in mind: for virtually all businesses, new customers will have a higher churn rate than mature customers. But what this means is that some form of segmentation is necessary to have a useful churn rate. For example you may want to only report the churn rate for customers who have been around for at least 90 days. Or you may want separate churn rates for all sorts of demographics and tenure. The aforementioned post by Custora has a great discussion of this that goes into greater detail.
If you don't apply some form of segmentation in your reporting you will find that your churn rate increases whenever your ratio of new customers to mature customers increases; even though it may be that the churn rates of both new and mature customers are dropping.
No aggregate is ever going to perfectly communicate a particular customer behaviour: an aggregate is lossy compression after all. But what you want to avoid are aggregates that hide big news, tell you something has changed when everything is still the same, or leave you with the opposite impression of what is actually happening. And remember, a change in aggregate will almost never tell you the entire story. What it tells you is there is a story to be told and now you need to find it.